[备份]CVE-2018-1271分析
简介
SpringMVC的一个目录穿越漏洞,或者说目录遍历漏洞。SpringMVC是Java开发界最常用的框架之一,当静态资源存放在Windows系统上时,攻击可以通过构造特殊URL导致目录遍历漏洞
漏洞有限制条件
- Server运行于Windows系统上
- 要使用file协议打开资源文件目录
漏洞复现
下载官方示例:https://github.com/spring-projects/spring-mvc-showcase
修改spring的版本
xxxxxxxxxx<properties> <java-version>1.8</java-version> <org.springframework-version>5.0.0.RELEASE</org.springframework-version> <org.aspectj-version>1.8.1</org.aspectj-version></properties>修改配置文件:org\springframework\samples\mvc\config\WebMvcConfig.java 这里的作用主要是配置资源映射,将url的/resources/**映射到file协议的resources下,其实真实开发场景一般不这样配
xxxxxxxxxxpublic void addResourceHandlers(ResourceHandlerRegistry registry) { registry.addResourceHandler("/resources/**").addResourceLocations("file:./src/main/resources/","/resources/");}使用mvn命令启动:mvn jetty:run(可在IDEA中配置启动方式为Maven后加入参数)
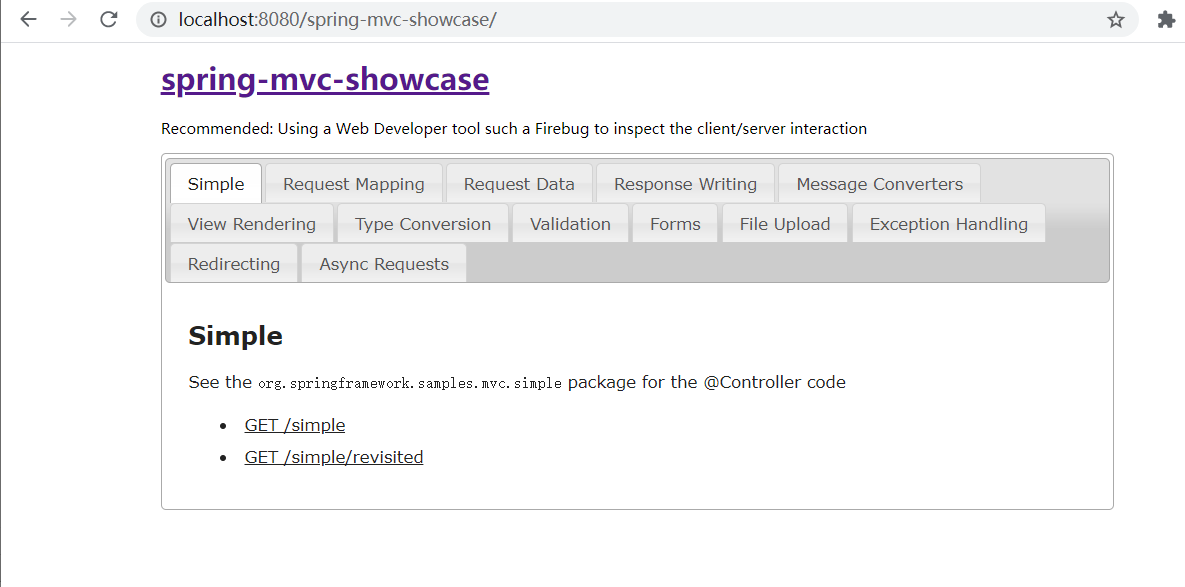
访问特殊url后成功读到文件:http://localhost:8080/spring-mvc-showcase/resources/%255c%255c..%255c/..%255c/..%255c/..%255c/..%255c/..%255c/..%255c/..%255c/..%255c/key.txt(由于我项目不在c盘,就没有读win.ini文件,自己新建了一个文件)
漏洞分析
org\springframework\web\servlet\resource\ResourceHttpRequestHandler.java
这里是处理请求的类,方法是handleRequest,一开始调用了getResource方法,跟入
xxxxxxxxxxResource resource = getResource(request);protected Resource getResource(HttpServletRequest request) throws IOException { String path = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE); ...... path = processPath(path); if (!StringUtils.hasText(path) || isInvalidPath(path)) { ...... }进入request.getAttribute有多种实现,不方便继续跟入分析,尝试动态调试,发现这里得到的path是进行一次url解码后的结果

后续有processPath和isInvalidPath方法对path进行处理和校验,其中processPath方法作用是处理斜杠的问题,比如多个斜杠或者丢失斜杠的问题,和这里无关系,程序经过它是path也没有变化。isInvalidPath是需要重点关注的
首先禁止了WEB-INF和META-INF等关键路径,然后处理是url(带有:/)的情况,最后是处理带有..的情况,而..正是目录遍历漏洞需要用到的
xxxxxxxxxxprotected boolean isInvalidPath(String path) { if (logger.isTraceEnabled()) { logger.trace("Applying \"invalid path\" checks to path: " + path); } if (path.contains("WEB-INF") || path.contains("META-INF")) { if (logger.isTraceEnabled()) { logger.trace("Path contains \"WEB-INF\" or \"META-INF\"."); } return true; } if (path.contains(":/")) { String relativePath = (path.charAt(0) == '/' ? path.substring(1) : path); if (ResourceUtils.isUrl(relativePath) || relativePath.startsWith("url:")) { if (logger.isTraceEnabled()) { logger.trace("Path represents URL or has \"url:\" prefix."); } return true; } } if (path.contains("..")) { path = StringUtils.cleanPath(path); if (path.contains("../")) { if (logger.isTraceEnabled()) { logger.trace("Path contains \"../\" after call to StringUtils#cleanPath."); } return true; } } return false;}跟入cleanPath方法,稍显复杂,实现的功能是将/foo/bar/../这样的路径转换为/foo/,其中delimitedListToStringArray方法会返回一个目录数组,比如上面的foo,bar,..。如果传入的是/foo/bar//../,数组中会有一个空值,cleanPath会解析为/foo/bar/,但系统中认为是/foo/。我们的payload%5c%5c..%5c/..%5c/..%5c/..%5c/..%5c/在这里按照/分割后,没有等于..的,所以cleanPath后原样返回
xxxxxxxxxxpublic static String cleanPath(String path) { if (!hasLength(path)) { return path; } String pathToUse = replace(path, WINDOWS_FOLDER_SEPARATOR, FOLDER_SEPARATOR);
// Strip prefix from path to analyze, to not treat it as part of the // first path element. This is necessary to correctly parse paths like // "file:core/../core/io/Resource.class", where the ".." should just // strip the first "core" directory while keeping the "file:" prefix. int prefixIndex = pathToUse.indexOf(":"); String prefix = ""; if (prefixIndex != -1) { prefix = pathToUse.substring(0, prefixIndex + 1); if (prefix.contains("/")) { prefix = ""; } else { pathToUse = pathToUse.substring(prefixIndex + 1); } } if (pathToUse.startsWith(FOLDER_SEPARATOR)) { prefix = prefix + FOLDER_SEPARATOR; pathToUse = pathToUse.substring(1); }
String[] pathArray = delimitedListToStringArray(pathToUse, FOLDER_SEPARATOR); List<String> pathElements = new LinkedList<>(); int tops = 0;
for (int i = pathArray.length - 1; i >= 0; i--) { String element = pathArray[i]; if (CURRENT_PATH.equals(element)) { // Points to current directory - drop it. } else if (TOP_PATH.equals(element)) { // Registering top path found. tops++; } else { if (tops > 0) { // Merging path element with element corresponding to top path. tops--; } else { // Normal path element found. pathElements.add(0, element); } } }
// Remaining top paths need to be retained. for (int i = 0; i < tops; i++) { pathElements.add(0, TOP_PATH); }
return prefix + collectionToDelimitedString(pathElements, FOLDER_SEPARATOR);}而上文的getResource方法的后半部分,又调用了一次isInvalidPath方法。此时path中还是包含%,所以成功进入了if,进行url解码后变成\\..\/..\/..\/..\/..\/..\/这种格式,经过cleanPath处理后,变成了//key.txt,返回false,通过了校验
xxxxxxxxxxif (path.contains("%")) { try { // Use URLDecoder (vs UriUtils) to preserve potentially decoded UTF-8 chars if (isInvalidPath(URLDecoder.decode(path, "UTF-8"))) { if (logger.isTraceEnabled()) { logger.trace("Ignoring invalid resource path with escape sequences [" + path + "]."); } return null; } } catch (IllegalArgumentException ex) { // ignore }}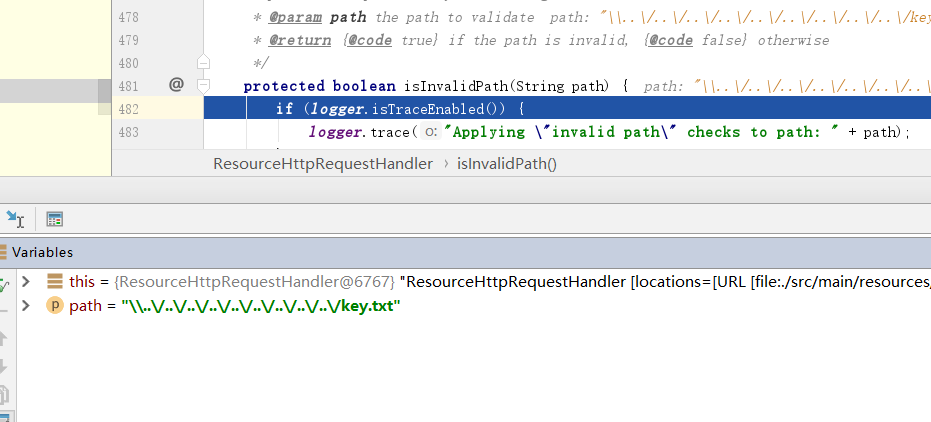
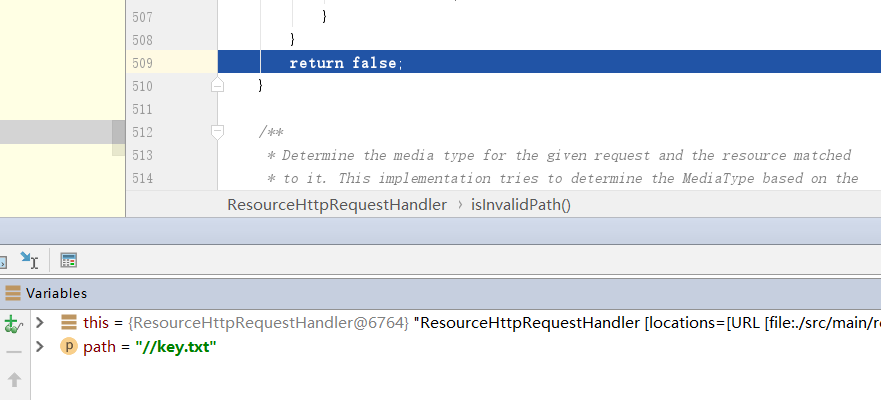
经过以上一系列复杂的处理后得到一个resource,path其实并没有变化,只是经过一次url解码后的结果:%5c%5c..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/key.txt
xxxxxxxxxxResourceResolverChain resolveChain = new DefaultResourceResolverChain(getResourceResolvers());Resource resource = resolveChain.resolveResource(request, path, getLocations());if (resource == null || getResourceTransformers().isEmpty()) { return resource;}ResourceTransformerChain transformChain = new DefaultResourceTransformerChain(resolveChain, getResourceTransformers());resource = transformChain.transform(request, resource);return resource;其中getLocations是我们之前配置的file:./src/main/resources/,跟入resolveResource,一条很长的调用链,最终到PathResourceResolver的getResource
xxxxxxxxxxprotected String resolveUrlPathInternal(String resourcePath, List<? extends Resource> locations, ResourceResolverChain chain) {
return (StringUtils.hasText(resourcePath) && getResource(resourcePath, locations) != null ? resourcePath : null);}private Resource getResource(String resourcePath, List<? extends Resource> locations) { for (Resource location : locations) { try { if (logger.isTraceEnabled()) { logger.trace("Checking location: " + location); } Resource resource = getResource(resourcePath, location); if (resource != null) { if (logger.isTraceEnabled()) { logger.trace("Found match: " + resource); } return resource; } else if (logger.isTraceEnabled()) { logger.trace("No match for location: " + location); } } catch (IOException ex) { logger.trace("Failure checking for relative resource - trying next location", ex); } } return null;}继续跟入getResource方法,
xxxxxxxxxxprotected Resource getResource(String resourcePath, Resource location) throws IOException { Resource resource = location.createRelative(resourcePath); if (resource.exists() && resource.isReadable()) { if (checkResource(resource, location)) { return resource; } else if (logger.isTraceEnabled()) { Resource[] allowedLocations = getAllowedLocations(); logger.trace("Resource path=\"" + resourcePath + "\" was successfully resolved " + "but resource=\"" + resource.getURL() + "\" is neither under the " + "current location=\"" + location.getURL() + "\" nor under any of the " + "allowed locations=" + (allowedLocations != null ? Arrays.asList(allowedLocations) : "[]")); } } return null;}public Resource createRelative(String relativePath) throws MalformedURLException { if (relativePath.startsWith("/")) { relativePath = relativePath.substring(1); } return new UrlResource(new URL(this.url, relativePath));}经过createRelative方法拼接后得到file:src/main/resources/%5c%5c..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/key.txt
xxxxxxxxxxpublic boolean exists() { try { URL url = getURL(); if (ResourceUtils.isFileURL(url)) { // Proceed with file system resolution return getFile().exists(); } ......在配置文件中修改为file:是因为isFileURL
xxxxxxxxxxpublic static boolean isFileURL(URL url) { String protocol = url.getProtocol(); return (URL_PROTOCOL_FILE.equals(protocol) || URL_PROTOCOL_VFSFILE.equals(protocol) || URL_PROTOCOL_VFS.equals(protocol));}跟入getFile
xxxxxxxxxxpublic File getFile() throws IOException { URL url = getURL(); if (url.getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) { return VfsResourceDelegate.getResource(url).getFile(); } return ResourceUtils.getFile(url, getDescription());}public static File getFile(URL resourceUrl, String description) throws FileNotFoundException { Assert.notNull(resourceUrl, "Resource URL must not be null"); if (!URL_PROTOCOL_FILE.equals(resourceUrl.getProtocol())) { throw new FileNotFoundException( description + " cannot be resolved to absolute file path " + "because it does not reside in the file system: " + resourceUrl); } try { return new File(toURI(resourceUrl).getSchemeSpecificPart()); } catch (URISyntaxException ex) { // Fallback for URLs that are not valid URIs (should hardly ever happen). return new File(resourceUrl.getFile()); }}在getSchemeSpecificPart方法中,有一次url的解码
xxxxxxxxxxpublic String getSchemeSpecificPart() { if (decodedSchemeSpecificPart == null) decodedSchemeSpecificPart = decode(getRawSchemeSpecificPart()); return decodedSchemeSpecificPart;}层层返回,验证通过,但路径还是没有变:/%5c%5c..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/..%5c/key.txt
handleRequest方法后续,验证通过,准备工作结束后,开始往response里面写入
x
this.resourceHttpMessageConverter.write(resource, mediaType, outputMessage);protected void writeInternal(Resource resource, HttpOutputMessage outputMessage) throws IOException, HttpMessageNotWritableException {
writeContent(resource, outputMessage);}protected void writeContent(Resource resource, HttpOutputMessage outputMessage) throws IOException, HttpMessageNotWritableException { try { InputStream in = resource.getInputStream();程序会在openConnection方法处进行URL解码
xxxxxxxxxxpublic InputStream getInputStream() throws IOException { URLConnection con = this.url.openConnection(); ResourceUtils.useCachesIfNecessary(con); try { return con.getInputStream(); }