简单学习JVM GC与类加载机制
写文时间:2020/08
引用计数算法
在对象中添加一个引用计数器,当有地方引用这个对象的时候,引用计数器的值就加1,当引用失效的时候(变量记为null),计数器的值就减1。但Java虚拟机中没有使用这种算法,这是由于如果堆内的对象之间相互引用,就始终不会发生计数器-1,那么就不会回收
可达性分析法
此算法的核心思想:通过一系列称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称为“引用链”,当一个对象到GC Roots没有任何的引用链相连时(从GC Roots)到这个对象不可达)时,证明此对象不可用
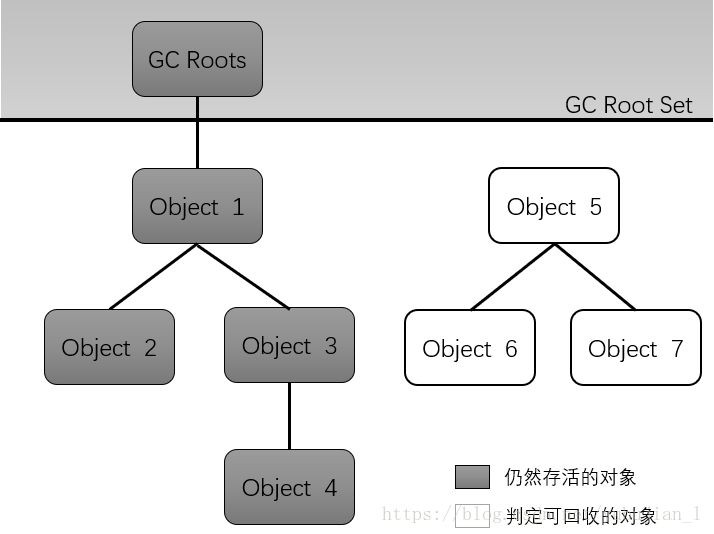
可作为GC Roots的对象:
(1)虚拟机栈
(2)方法区的类属性所引用的对象
(3)方法区中常量所引用的对象
(4)本地方法栈中引用的对象
垃圾回收算法
复制算法
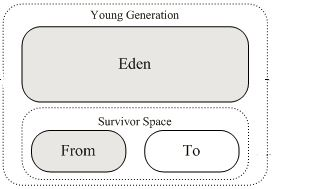
复制算法是将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,浪费较大。复制算法的执行过程如下图所示:

现在的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象98%是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性的复制到另外一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性的复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”
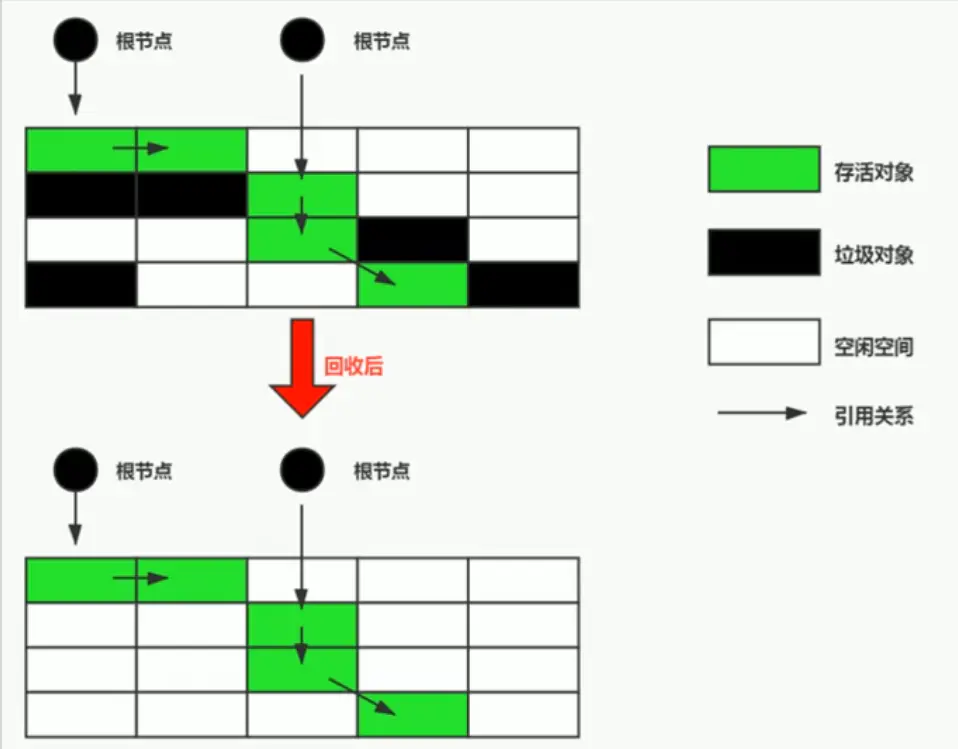
标记清除算法
当堆中的有效内存空间被耗尽的时候,就会停止整个程序(也被称为stop the world)
然后进行两项工作:第一项则是标记,第二项则是清除。
标记:从引用根结点开始遍历,标记所有被引用的对象。一般是在对象的Header中记录为可达对象
清除:对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收
有效率问题和空间问题:标记的空间被清除后,会造成内存中出现越来越多的不连续空间。当要分配一个大对象的时候,在进行寻址的要花费很多时间,可能会再一次触发垃圾回收
标记整理算法
对于老年代,回收的垃圾较少时,如果采用复制算法,则效率较低。标记整理算法的标记操作和“标记-清除”算法一致,后续操作不只是直接清理对象,而是在清理无用对象完成后让所有存活的对象都向一端移动,并更新引用其对象的指针
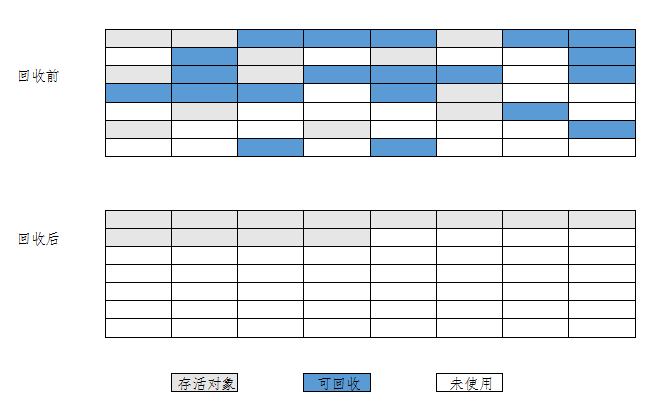
很显然,整理这一下需要时间,所以与标记清除算法相比,这一步花费了不少时间,但从长远来看,这一步还是很有必要的
分代收集算法
针对不同的年代进行不同算法的垃圾回收,针对新生代选择复制算法,对老年代选择标记整理算法
垃圾收集器
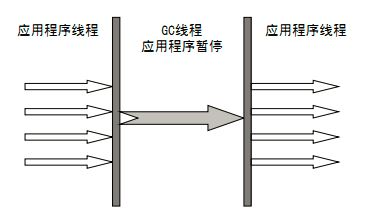
Serial收集器
单线程垃圾收集器、最基本、发展最悠久。它的单线程的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。偶尔用在桌面应用中
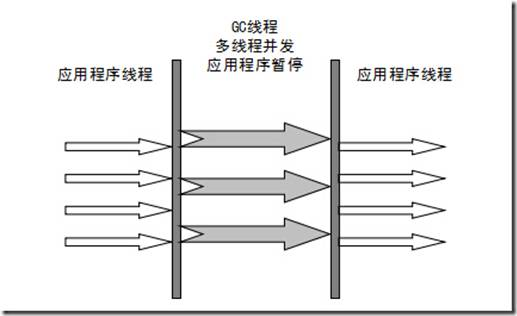
ParNew收集器
可多线程收集垃圾,收集新生代,使用收集算法
Parallel收集器
多线程收集垃圾,收集新生代,使用收集算法。Parallel收集器更关注系统的吞吐量,可以通过参数来打开自适应调节策略
吞吐量:CPU用于运行用户代码的时间与CPU消耗的总时间的比值。
吞吐量 = (执行用户代码时间)/(执行用户代码时间+垃圾回收占用时间)
-XX:MaxGCPauseMillis 垃圾收集器最大停顿的时间,但最大停顿时间过短必然会导致新生代的内存大小变小,垃圾回收频率变高,效率可能降低
-XX:CGTIMERatio 吞吐量大小(0-100),默认为99
CMS收集器
Concurrent Mark Sweep,采用标记-清除算法,用于老年代,常与ParNew协同工作。优点在于并发收集与低停顿
注:并行是指同一时刻同时做多件事情,而并发是指同一时间间隔内做多件事情
工作过程

初始标记:
标记老年代中所有的GC Roots对象和年轻代中活着的对象引用到的老年代的对象,时间短
并发标记:
从“初始标记”阶段标记的对象开始找出所有存活的对象
重新标记:
用来处理前一个阶段因为引用关系改变导致没有标记到的存活对象,时间短
并发清理:
清除那些没有标记的对象并且回收空间
缺点:占用大量的cpu资源、无法处理浮点垃圾、出现Concurrent MarkFailure、空间碎片
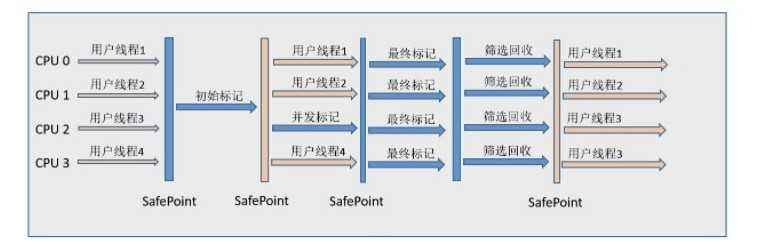
G1收集器
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一,早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术
优势:并行(多核CPU)与并发
分代收集(新生代和老年代区分不明显)
空间整合
限制收集范围,可预测的停顿
步骤:初始标记、并发标记、最终标记和筛选回收
性能调优案例
案例一
背景:绩效考核系统,会针对每一个考核员工生成一个各考核点的考核结果,形成一个Excel文档,供用户下载。文档中包含用户提交的考核点信息以及分析信息,Excel文档由用户请求的时候生成,下载并保存在内存服务器一份。64G内存
问题:经常有用户反映长时间卡顿的问题
处理思路:
优化SQL(无效)
监控CPU
监控内存发现经常发生Full GC 20-30s
运行时产生大对象(每个教师考核的数据WorkBook),直接放入老年代,MinorGC不会去清理,会导致FullGC,且堆内存分配太大,时间过长
解决方案:部署多个web容器,每个web容器的堆内存4G,单机TomCat集群
案例二
背景:简单数据抓取系统,抓取网络上的一些数据,分发到其它应用
问题:不定期内存溢出,把堆内存加大,无济于事,内存监控也正常
处理方法:NIO使用了堆外内存,堆外内存无法垃圾回收,导致溢出
类加载
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制
JVM是懒加载(节约系统资源)
类加载的时机
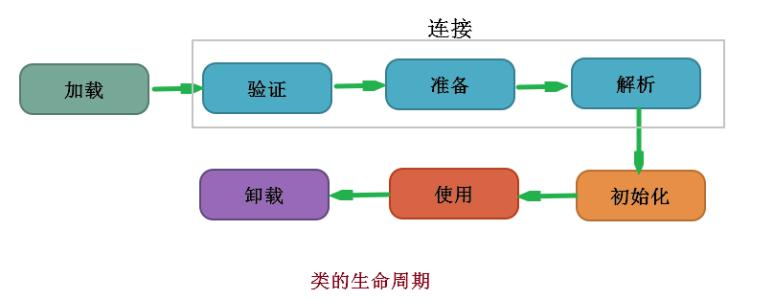
加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,但解析阶段则不一定,它在某些情况下可以在初始化阶段之后再开始
虚拟机规范严格规定了有且只有五种情况必须立即对类进行“初始化”:
使用new关键字实例化对象的时候、读取或设置一个类的静态字段的时候,已经调用一个类的静态方法的时候
使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有初始化,则需要先触发其初始化
当初始化一个类的时候,如果发现其父类没有被初始化就会先初始化它的父类
当虚拟机启动的时候,用户需要指定一个要执行的主类(就是包含main()方法的那个类),虚拟机会先初始化这个类
使用Jdk1.7动态语言支持的时候的一些情况
xxxxxxxxxxpublic class Parent { static { System.out.println("父类加载..."); }}
public class Child extends Parent{ static { System.out.println("子类加载..."); } public static void main(String[] args) { System.out.println("子类运行..."); }}
运行结果:父类加载...子类加载...子类运行...除此之外所有引用类的方式都不会触发初始化称为被动引用,下面是3个被动引用例子:
(1)通过子类引用父类静态字段,不会导致子类初始化
(2)通过数组定义引用类,不会触发此类的初始化
xxxxxxxxxxpublic class SuperClass { static { System.out.println("SuperClass(父类)被初始化了。。。"); } public static int value = 66;}
public class Subclass extends SuperClass { static { System.out.println("Subclass(子类)被初始化了。。。"); }}
public class Test1 {
public static void main(String[] args) {
// 1:通过子类调用父类的静态字段不会导致子类初始化 // System.out.println(Subclass.value);//SuperClass(父类)被初始化了。。。 // 2:通过数组定义引用类,不会触发此类的初始化 SuperClass[] superClasses = new SuperClass[3]; // 3:通过new 创建对象,可以实现类初始化,必须把1下面的代码注释掉才有效果不然经过1的时候类已经初始化了,下面这条语句也就没用了。 //SuperClass superClass = new SuperClass(); }
}(3)常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用定义常量的类,因此不会触发定义常量的类的初始化
加载
加载过程:
(1)通过类型的完全限定名,产生一个代表该类型的二进制数据流(没有指明从哪里获取、怎样获取,是一个非常开放的平台),加载源包括:文件(Class文件,Jar文件)、网络、计算生成(代理$Proxy)、由其它文件生成(jsp)、数据库中
(2)解析这个二进制数据流为方法区内的运行时数据结构
(3)创建一个表示该类型的java.lang.Class类的实例,作为方法区这个类的各种数据的访问入口
校验
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全
从整体上看,验证阶段大致上会完成4个阶段的校验工作:文件格式、元数据、字节码、符号引用。可以通过设置参数略过
准备
准备阶段正式为类变量分配内存并设置变量的初始值。这些变量使用的内存都将在方法区中进行分配
注:这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中
初始值通常是数据类型的零值
对于:public static int value = 123,那么变量value在准备阶段过后的初始值为0而不是123,这时候尚未开始执行任何java方法,把value赋值为123的动作将在初始化阶段才会被执行
对于:public static final int value = 123,编译时Javac将会为value生成ConstantValue(常量)属性,在准备阶段虚拟机就会根据ConstantValue的设置将value赋值为123
解析
解析阶段是虚拟机将常量池中的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行
符号引用(Symbolic References): 符号引用以一组符号来描述所引用的目标,符号可以是符合约定的任何形式的字面量,符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中
直接引用(Direct References): 直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用与虚拟机实现的内存布局相关,引用的目标必定已经在内存中存在
初始化
到了初始化的阶段,才是真正开始执行类中定义的Java程序代码
(1)初始化阶段是执行类构造器()方法的过程,它是由编译器自动收集类中的所有类变量的赋值动作和静态语句块static{}中的语句合并产生的。静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但不能访问
xxxxxxxxxxpublic class InitTest1 { static { i = 0; //给变量赋值可以正常编译 System.out.println(i); //编译器提示:“非法向前引用” } static int i = 1;}(2)父类中定义的静态语句块要优于子类的变量赋值操作
(3)如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生产()方法。
(4)虚拟机会保证一个类的()方法在多线程环境中被正确的加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行()方法完毕
类加载器
对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性。如果两个类来源于同一个Class文件,只要加载它们的类加载器不同,那么这两个类就必定不相等
启动类加载器(Bootstrap ClassLoader): 这个类加载器负责将存放在\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。getClassLoader()方法返回null
扩展类加载器(Extension ClassLoader): 这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器
应用程序类加载器(Application ClassLoader): 这个类加载器由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器
双亲委派模型
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器
这里类加载器之间的父子关系一般不会以继承的关系来实现,而都是使用组合的关系复用父类加载器的代码
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载

使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是java类随着它的类加载器一起具备了一种带有优先级的层次关系
双亲委派模型的实现:
xxxxxxxxxxprotected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { //1 首先检查类是否被加载 Class c = findLoadedClass(name); if (c == null) { try { if (parent != null) { //2 没有则调用父类加载器的loadClass()方法; c = parent.loadClass(name, false); } else { //3 若父类加载器为空,则默认使用启动类加载器作为父加载器; c = findBootstrapClass0(name); } } catch (ClassNotFoundException e) { //4 若父类加载失败,抛出ClassNotFoundException 异常后 c = findClass(name); } } if (resolve) { //5 再调用自己的findClass() 方法。 resolveClass(c); } return c;}java.lang.ClassLoader 的 loadClass() 实现了双亲委派模型的逻辑,因此自定义类加载器一般不去重写它,但是需要重写 findClass() 方法